Scenario
- Ambiente oracle single instance
- Database oracle versione 12.1.0.2
- Cluster GRID oracle versione 19.7.0.0
- Sistema Operativo Oracle Linux 7.8
- Storage VNX 5100 con connessione in fibra
- Directory di lavoro: /home/oracle/perf_test
- Direcory logs: /home/oracle/perf_test/log
- Database connection: MYDB
Obiettivo
Ridurre le attese su una tabella in fase di inserimento massivo nell’ipotesi che questo venga effettuato da un numero elevato di processi paralleli generando una contention a livello di accesso alla tabella stessa e agli oggetti ad essa correlati.
Sommario test eseguiti
Numero di processi che effettuano le insert: 400
Numero di righe inserite per ogni processo: 10.000
Totale righe inserite per ogni ciclo: 4.000.000
Risultato dei test con tuning progressivo:
| N° Test | Secondi | Struttura tabella | Struttura indici |
| 1 | 26 | Semplice | Semplice |
| 2 | 25 | Partizionamento hash | Semplice |
| 3 | 10 | Partizionamento hash | Partizionamento hash |
| 4 | 8 | Partizionamento hash | Partizionamento hash indici reverse |
| 5 | 9 | Partizionamento range sottopartizioni hash | Partizionamento hash indici reverse |
Preparazione ambiente di lavoro:
Creiamo utenza, tabella e tablespaces necessari all’esecuzione del test
Tablespaces per tabella e indici:
create tablespace t01 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace t02 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace t03 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace t04 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace t05 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace t06 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace t07 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace t08 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx01 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx02 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx03 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx04 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx05 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx06 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx07 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
create tablespace tx08 datafile '+DG_DATA' size 128M autoextend on next 128M maxsize unlimited;
Utenza e grant relativi
create user perf_user identified by B3stT3st default tablespace t01;
grant connect, resource to perf_user;
grant create sequence to perf_user;
alter user perf_user quota unlimited on t01;
alter user perf_user quota unlimited on t02;
alter user perf_user quota unlimited on t03;
alter user perf_user quota unlimited on t04;
alter user perf_user quota unlimited on t05;
alter user perf_user quota unlimited on t06;
alter user perf_user quota unlimited on t07;
alter user perf_user quota unlimited on t08;
alter user perf_user quota unlimited on tx01;
alter user perf_user quota unlimited on tx02;
alter user perf_user quota unlimited on tx03;
alter user perf_user quota unlimited on tx04;
alter user perf_user quota unlimited on tx05;
alter user perf_user quota unlimited on tx06;
alter user perf_user quota unlimited on tx07;
alter user perf_user quota unlimited on tx08;
Tabella per il test:
Drop table perf_user.block_test;
Create table perf_user.block_test
(
chiave number,
Adesso timestamp,
Nickname varchar(30)
);
CREATE UNIQUE INDEX PERF_USER.PK_BLOCK_TEST_INDX ON PERF_USER.BLOCK_TEST (CHIAVE) tablespace tx01;
CREATE index perf_user.adesso_indx ON PERF_USER.BLOCK_TEST (adesso) tablespace tx01;
CREATE index perf_user.Nickname_indx ON PERF_USER.BLOCK_TEST (Nickname) tablespace tx01;
Alter table perf_user.block_test add constraint pk_block_test primary key (chiave);
Sequence:
Viene creata una sequence da usare per la chiave primaria:
Drop sequence perf_user.block_test_seq;
create sequence perf_user.block_test_seq start with 1000000;
Script accesso DB per il test massivo (block_test.sh):
Lo script genera un processo che inserisce un numero di righe pari a NUM_ROWS.
#!/bin/bash
NUM_ROWS=10000
sqlplus -S perf_user/B3stT3st@MYDB <<EOF
set serverout on echo on
ALTER SESSION SET TIMED_STATISTICS = TRUE;
ALTER SESSION SET MAX_DUMP_FILE_SIZE='UNLIMITED';
Declare
I number :=0;
Maxloop number := $NUM_ROWS;
MaxCommit number := 10;
Curr_chiave number :=0;
v_nick varchar(50);
v_random_str varchar(30) :='';
v_contatore number :=0;
Begin
For i in 1 .. Maxloop
Loop
v_random_str:=to_char(systimestamp,'YYYYMMDDHH24MISSFF');
v_nick := v_random_str || '_' || I;
Select block_test_seq.nextval into Curr_chiave from dual;
Insert into block_test values (Curr_chiave,systimestamp,v_nick);
If mod (I,Maxcommit)=0 then
Commit;
End if;
End loop;
commit;
End;
/
Exit
EOF
exit 0
Script Principale per il test massivo (main_block_test.sh):
Lo script lancia un certo numero di processi paralleli che si occuperanno di effettuare le insert nel database.
#!/bin/bash
start=$(date +%s%N);
export NUM_PROCESSES=400
export LAV_DIR=/home/oracle/perf_test
export LOG_FILE=$LAV_DIR/log/test.log.$(date '+%Y%m%d.%H%M%S')
export LOG_COUNTER_FILE=$LAV_DIR/block_test_counter.log
echo "BEGIN = " $(date)
echo "."
# -- execution loop
for (( c=1; c<=$NUM_PROCESSES; c++ ))
do
$LAV_DIR/block_test.sh 1>> $LOG_FILE &
done
echo "Background insert in progress ... "
echo "."
# -- blocco per il monitoraggio dei processi attivi
while [[ -n $(jobs -r) ]]
do
job_count=$(jobs -r|wc -l)
done
job_count=$(jobs -r|wc -l)
echo "Processes running = " $job_count
end=$(date +%s%N)
elapsed=$(echo "($end-$start)/1000000000" | bc -l )
echo "."
echo "Elapsed time = $elapsed"
echo "."
echo "END = " $(date)
TEST 1:
Eseguiamo il test senza nessuna ottimizzazione:
- Tabella:
- Struttura: Semplice
- Partizioni: Nessuna
- Indici:
- Struttura: Semplice
- Partizioni: Nessuna
Risultati test:
$ ./main_block_test.sh
Table truncated.
BEGIN = Thu Feb 4 16:47:36 CET 2021
.
Background insert in progress ...
Processes running = 0
.
Elapsed time = 25.82082612900000000000
.
END = Thu Feb 4 16:48:01 CET 2021
come si vede da OEM c’è un enorme contesa di accesso alla tabella e un elevato numero di sessioni attive contempopranee (picchi di oltre 250):
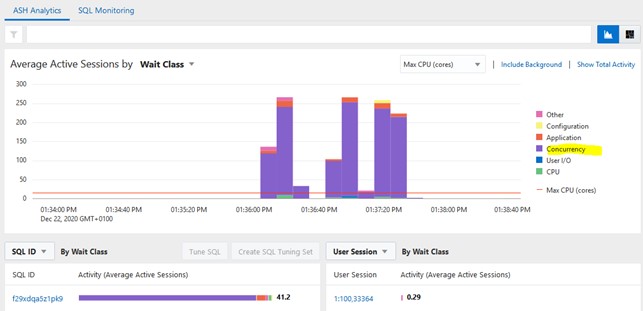
Infatti analizzando gli eventi di attesa durante l’esecuzione osserviamo attese importanti:
select event, count(1), sum(time_waited)/1000/1000 time_in_sec
from v$active_session_history
where sample_time between to_date('20210204164700','yyyymmddhh24miss')
and to_date('20210204164900','yyyymmddhh24miss') group by event order by 3 desc;
EVENT COUNT(1) TIME_IN_SEC
---------------------------------------------------------------- ---------- -----------
enq: TX - index contention 2204 91.878997
buffer busy waits 2667 79.717317
enq: TX - row lock contention 240 48.679355
enq: TX - allocate ITL entry 13 7.654085
library cache load lock 1 .238075
log file sync 1 .011662
library cache lock 1 .006748
rdbms ipc reply 1 .002602
control file sequential read 1 .000438
buffer deadlock 4 0
41 0
null event 1 0
TEST 2:
Un’ottima strategia per ridurre la contesa nell’accesso ai blocchi è utilizzare il partizionamento hash in modo da distribuire i dati su più file e ridurre la contesa del blocco:
- Tabella:
- Struttura: Partizionata
- Partizioni: Partizioni hash su tablespace differenti
- Indici:
- Struttura: Semplice
- Partizioni: Nessuna
ATTENZIONE!!!
Molto importante ricordarsi che il partizionamento hash richiede un numero di partizioni pari a 2n per massimizzare le prestazioni!
Creiamo quindi la tabella con partizionamento hash sul campo chiave.
Drop table perf_user.block_test;
Create table perf_user.block_test
(
chiave number,
Adesso timestamp,
Nickname varchar(30)
)
Partition by hash (chiave)
(
partition p01 tablespace t01,
partition p02 tablespace t02,
partition p03 tablespace t03,
partition p04 tablespace t04,
partition p05 tablespace t05,
partition p06 tablespace t06,
partition p07 tablespace t07,
partition p08 tablespace t08
);
CREATE UNIQUE INDEX PERF_USER.PK_BLOCK_TEST_INDX ON PERF_USER.BLOCK_TEST (CHIAVE) tablespace tx01;
CREATE index perf_user.adesso_indx ON PERF_USER.BLOCK_TEST (adesso) tablespace tx01;
CREATE index perf_user.Nickname_indx ON PERF_USER.BLOCK_TEST (Nickname) tablespace tx01;
Alter table perf_user.block_test add constraint pk_block_test primary key (chiave);
Risultati test:
$ ./main_block_test.sh
Table truncated.
BEGIN = Thu Feb 4 16:54:01 CET 2021
.
Background insert in progress ...
Processes running = 0
.
Elapsed time = 25.48407368300000000000
.
END = Thu Feb 4 16:54:26 CET 2021
Purtroppo come si vede la distribuzione di carico non ha migliorato le tempistiche e questo a causa del fatto che il partizionamento non è stato applicato anche sugli indici.
TEST 3:
Effettuiamo la distribuzione su diversi tablespace anche sugli indici:
- Tabella:
- Struttura: Partizionata
- Partizioni: Partizioni hash su tablespace differenti
- Indici:
- Struttura: Partizionata
- Partizioni: Partizioni hash su tablespace differenti
Struttura tabella:
Drop table perf_user.block_test;
Create table perf_user.block_test
(
chiave number,
Adesso timestamp,
Nickname varchar(30)
)
Partition by hash (chiave)
(
partition p01 tablespace t01,
partition p02 tablespace t02,
partition p03 tablespace t03,
partition p04 tablespace t04,
partition p05 tablespace t05,
partition p06 tablespace t06,
partition p07 tablespace t07,
partition p08 tablespace t08
);
CREATE UNIQUE INDEX PERF_USER.PK_BLOCK_TEST_INDX ON PERF_USER.BLOCK_TEST (CHIAVE)
GLOBAL PARTITION BY HASH (CHIAVE)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
);
CREATE index perf_user.adesso_indx ON PERF_USER.BLOCK_TEST (adesso)
GLOBAL PARTITION BY HASH (adesso)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
);
CREATE index perf_user.Nickname_indx ON PERF_USER.BLOCK_TEST (Nickname)
GLOBAL PARTITION BY HASH (Nickname)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
);
Alter table perf_user.block_test add constraint pk_block_test primary key (chiave);
Risultati test:
$ ./main_block_test.sh
Table truncated.
BEGIN = Thu Feb 4 17:21:15 CET 2021
.
Background insert in progress ...
Processes running = 0
.
Elapsed time = 9.82258364100000000000
.
END = Thu Feb 4 17:21:25 CET 2021
come si vede da OEM c’è una notevole riduzione dela contesa di accesso ai dati e una riduzione delle sessioni attive contemporanee con un picco di 110 circa:

Come si osserva anche analizzando gli eventi di attesa:
select event, count(1), sum(time_waited)/1000/1000 time_in_sec
from v$active_session_history
where sample_time between to_date('20210204172100','yyyymmddhh24miss')
and to_date('20210204172200','yyyymmddhh24miss') group by event order by 3 desc;
EVENT COUNT(1) TIME_IN_SEC
---------------------------------------------------------------- ---------- -----------
library cache lock 150 30.927272
buffer busy waits 529 22.030492
enq: TX - index contention 330 15.782876
enq: TX - row lock contention 44 1.653151
library cache: mutex X 21 .081175
log file sync 3 .026696
db file sequential read 2 .008657
null event 1 0
34 0
9 rows selected.
TEST 4:
Effettuiamo la distribuzione su diversi tablespace anche sugli indici ma aggiungendo l’opzione reverse:
- Tabella:
- Struttura: Partizionata
- Partizioni: Partizioni hash su tablespace differenti
- Indici:
- Struttura: Partizionata, reverse index
- Partizioni: Partizioni hash su tablespace differenti
Struttura tabella:
Drop table perf_user.block_test;
Create table perf_user.block_test
(
chiave number,
Adesso timestamp,
Nickname varchar(30)
)
Partition by hash (chiave)
(
partition p01 tablespace t01,
partition p02 tablespace t02,
partition p03 tablespace t03,
partition p04 tablespace t04,
partition p05 tablespace t05,
partition p06 tablespace t06,
partition p07 tablespace t07,
partition p08 tablespace t08
);
CREATE UNIQUE INDEX PERF_USER.PK_BLOCK_TEST_INDX ON PERF_USER.BLOCK_TEST (CHIAVE)
GLOBAL PARTITION BY HASH (CHIAVE)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
) reverse;
CREATE index perf_user.adesso_indx ON PERF_USER.BLOCK_TEST (adesso)
GLOBAL PARTITION BY HASH (adesso)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
) reverse;
CREATE index perf_user.Nickname_indx ON PERF_USER.BLOCK_TEST (Nickname)
GLOBAL PARTITION BY HASH (Nickname)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
) reverse;
Alter table perf_user.block_test add constraint pk_block_test primary key (chiave);
Risultati test:
$ ./main_block_test.sh
Table truncated.
BEGIN = Thu Feb 4 17:43:44 CET 2021
.
Background insert in progress ...
Processes running = 0
.
Elapsed time = 8.40423622400000000000
.
END = Thu Feb 4 17:43:51 CET 2021
come si vede da OEM c’è una riduzione della contesa di accesso ai dati e il picco di sessioni contemporanee scende a circa 70 e tempi di attesa inferiori:

Come si osserva anche analizzando gli eventi di attesa:
select event, count(1), sum(time_waited)/1000/1000 time_in_sec
from v$active_session_history
where sample_time between to_date('20210204174300','yyyymmddhh24miss')
and to_date('20210204174400','yyyymmddhh24miss') group by event order by 3 desc;
EVENT COUNT(1) TIME_IN_SEC
---------------------------------------------------------------- ---------- -----------
enq: HW - contention 119 14.904408
library cache lock 49 11.033313
enq: TX - index contention 249 5.940069
buffer busy waits 217 3.121323
enq: TX - row lock contention 29 1.624015
enq: RO - fast object reuse 1 .015547
db file sequential read 4 .01049
library cache: mutex X 14 .00954
buffer deadlock 2 0
null event 2 0
log file sync 12 0
46 0
SQL*Net break/reset to client 1 0
TEST 5:
Effettuiamo adesso un test che ha come obiettivo la possibilità di pianificare future archiviazioni in base alla data ma continuando a sfruttare le potenzialità del partizionamento hash:
Scenario:
- Tabella:
- Struttura: Partizionata
- Partizioni: Partizioni per data e sottopartzioni hash su tablespace differenti
- Indici:
- Struttura: Partizionata, reverse index
- Partizioni: Partizioni hash su tablespace differenti
Modifiche strutturali:
Drop table perf_user.block_test;
Create table perf_user.block_test
(
chiave number,
Adesso timestamp,
Nickname varchar(30)
)
Partition by range (Adesso)
subpartition by hash (chiave)
SUBPARTITION TEMPLATE
(
SUBPARTITION bt01 TABLESPACE t01,
SUBPARTITION bt02 TABLESPACE t02,
SUBPARTITION bt03 TABLESPACE t03,
SUBPARTITION bt04 TABLESPACE t04,
SUBPARTITION bt05 TABLESPACE t05,
SUBPARTITION bt06 TABLESPACE t06,
SUBPARTITION bt07 TABLESPACE t07,
SUBPARTITION bt08 TABLESPACE t08
)
(
PARTITION p1 VALUES LESS THAN
(to_timestamp('20210101000000','yyyymmddhh24miss')),
PARTITION p2 VALUES LESS THAN
(to_timestamp('20210201000000','yyyymmddhh24miss')),
PARTITION p3 VALUES LESS THAN
(to_timestamp('20210301000000','yyyymmddhh24miss')),
PARTITION pMAX VALUES LESS THAN (MAXVALUE)
);
CREATE UNIQUE INDEX PERF_USER.PK_BLOCK_TEST_INDX ON PERF_USER.BLOCK_TEST (CHIAVE)
GLOBAL PARTITION BY HASH (CHIAVE)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
) reverse;
CREATE index perf_user.adesso_indx ON PERF_USER.BLOCK_TEST (adesso)
GLOBAL PARTITION BY HASH (adesso)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
) reverse;
CREATE index perf_user.Nickname_indx ON PERF_USER.BLOCK_TEST (Nickname)
GLOBAL PARTITION BY HASH (Nickname)
(
PARTITION ibt01 TABLESPACE tx01
NOCOMPRESS
, PARTITION ibt02 TABLESPACE tx02
NOCOMPRESS
, PARTITION ibt03 TABLESPACE tx03
NOCOMPRESS
, PARTITION ibt04 TABLESPACE tx04
NOCOMPRESS
, PARTITION ibt05 TABLESPACE tx05
NOCOMPRESS
, PARTITION ibt06 TABLESPACE tx06
NOCOMPRESS
, PARTITION ibt07 TABLESPACE tx07
NOCOMPRESS
, PARTITION ibt08 TABLESPACE tx08
NOCOMPRESS
) reverse;
Alter table perf_user.block_test add constraint pk_block_test primary key (chiave);
Risultati test:
$ ./main_block_test.sh
Table truncated.
BEGIN = Thu Feb 4 18:02:56 CET 2021
.
Background insert in progress ...
Processes running = 0
.
Elapsed time = 8.70257120200000000000
.
END = Thu Feb 4 18:03:05 CET 2021
Come si può osservare rispetto il test precedente abbiamo un ulteriore anche se lieve miglioramento delle prestazioni e inoltre si ha il vantaggio di poter spostare le partizioni per data in base alle necessità di eventuale storicizzazione.

Così come anche analizzando i tempi di attesa si osserva il miglioramento:
select event, count(1), sum(time_waited)/1000/1000 time_in_sec
from v$active_session_history
where sample_time between to_date('20210204180200','yyyymmddhh24miss')
and to_date('20210204180400','yyyymmddhh24miss') group by event order by 3 desc;
EVENT COUNT(1) TIME_IN_SEC
---------------------------------------------------------------- ---------- -----------
library cache lock 206 37.128257
buffer busy waits 148 2.559743
enq: TX - row lock contention 30 2.292024
enq: TX - index contention 159 2.03988
log file sync 11 .109333
library cache: mutex X 25 .047904
db file sequential read 5 .040854
latch free 2 .00725
enq: TX - allocate ITL entry 1 0
26 0
null event 1 0
buffer deadlock 2 0
Conclusioni
L’utilizzo delle sottopartizioni hash e degli indici reverse distribuiti su tablespaces differenti e quindi su file fisici differenti aiuta notevolmente a ridurre la contesa delle risorse e a velocizzare l’inserimento massivo di processi paralleli all’interno di una stessa tabella.

Commenti recenti